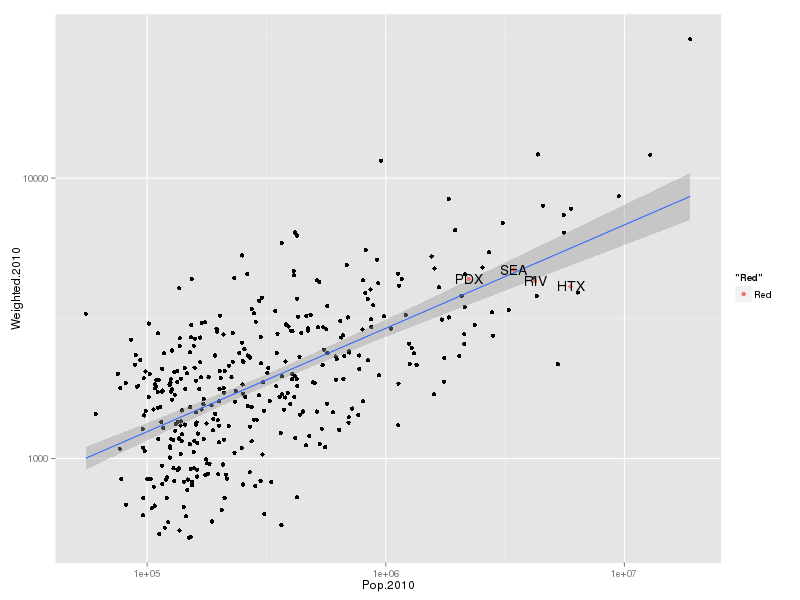
Project Connect has generously shared most of its intermediate findings. I took the opportunity to look over some of their work over the last couple days. It’s a complicated task, as they included a vast number of measures, far more than truly needed for the task. In deciding how to report its results, AURA has disagreed with Project Connect on a number of areas. Some of these include:
- After it began its analysis, Project Connect decided to change the definition of the subcorridors, such that the population-rich, transit-heavy West Campus was no longer included in the Lamar and MoPac subcorridors.
- Project Connect not only overweights future measures compared to present measures, it actually underweights present measures so much so that, in many areas, a subcorridor projected to have more congestion or density in 2010 and 2030 may be ranked lower than a subcorridor with less congestion or density in both time periods, just because the weaker subcorridor is projected to add more people. Put another way, in their methodology, two birds in hand are worth one in the bush. See my previous post for details.
- Project Connect included I-35 information in the congestion figures for many of the subcorridors, without regard to whether a more significant fraction of highway drivers are nonlocal and less likely to get out and use a train than locals.
I have rerun Project Connect’s scoring methodology to account for each of these issues. I found that highway data was not important for congestion measures, and resulted in similar measurements to Project Connect’s. However, both the hyper-overweighting of the future and the exclusion of West Campus data were significant issues with Project Connect’s methodology, masking the strength of the Lamar subcorridor to the benefit of the Highland subcorridor. Merely removing the hyperoverweighting of the future, but keeping the future weighted stronger than the present, and including West Campus in the analysis, results in the intuitive result that the Lamar subcorridor is ranked highest, East Riverside second, and Highland, Mueller, and East Austin lumped together.
I’m not going to say that these are the final results I believe in yet. It wasn’t until I dug into Project Connect’s methodology that I noticed some of the strange preferences they embody, such as the hyperoverweighting of the future compared to the present. Most likely, using a bottom-up method of selecting a few of the most salient measures from their analysis will be more productive in making a final selection, something that Julio has started very ably.
However, my analysis here makes one thing clear: the repeated assertion that the numbers point to the same conclusion any which way you dice them is nonsense. It actually takes torturing the data quite a bit to result in the particular recommendation that they did: merely failing to hyperoverweight the future to the present or failing to exclude West Campus from the analysis changes the results materially.
Methodology
I downloaded the data from Project Connect. I used the measure weightings from this document and the index weightings from this document. I validated my intermediate results by using the weightings from the survey. For the West Campus data, I used the “West Campus” tab with only one change: I set the “consistency” measure for MoPac and Lamar subcorridors to 4 and 8–adding in the “2” result for West Campus with the original “2” and “6” results for the two subcorridors, in place of the 0’s in the spreadsheet, which I believe was in error. For the “overweighted future” scores, I set the weightings for all measures that were “increase from 2010 to 2030” to “0” and left the 2030 and 2010 weightings alone. (2030 was already overweighted compared to the present; it was the increase that was responsible for the hyperoverweighting.)
I will continue to try to do analysis on this so that we can understand a clear story about what the data means, and not just “what are the final results.” If you have particular questions you’d like me to answer, please let me know in the comments or on twitter or any which other way you know to reach me. The code is in R and is available upon request.